

Eine starke Developer Experience (DevEx) ist kein Nice-to-have, sondern ein entscheidender Wettbewerbsfaktor. Reibungslose Prozesse und moderne Tools steigern die Produktivität der Entwicklungsteams, beschleunigen Innovation und erhöhen die Attraktivität als Arbeitgeber [1], [2]. Dieser Beitrag zeigt, warum CIOs und CTOs DevEx zur Chefsache machen sollten und welche Kernbausteine eine erstklassige DevEx ausmachen – von Internal Developer Platforms über Golden Paths bis zu KI-Assistenz.
Angesichts des anhaltenden Fachkräftemangels und der digitalen Disruption rückt die Developer Experience in den Fokus der Unternehmensstrategie. Studien zeigen einen klaren Zusammenhang zwischen Engineering Performance und Business-Erfolg: Eliteteams mit optimierter DevEx liefern Software bis zu 973-mal häufiger aus und verkürzen die Lead Time um Größenordnungen [3] – sie können neue Ideen also wesentlich schneller in Kundennutzen verwandeln. Solche High-Performer erreichen konsequent bessere Geschäftsergebnisse und übertreffen ihre Ziele häufiger [3]. Umgekehrt führen schlechte Entwicklererfahrungen zu Verzögerungen, Qualitätsproblemen und Demotivation (Abb. 1).
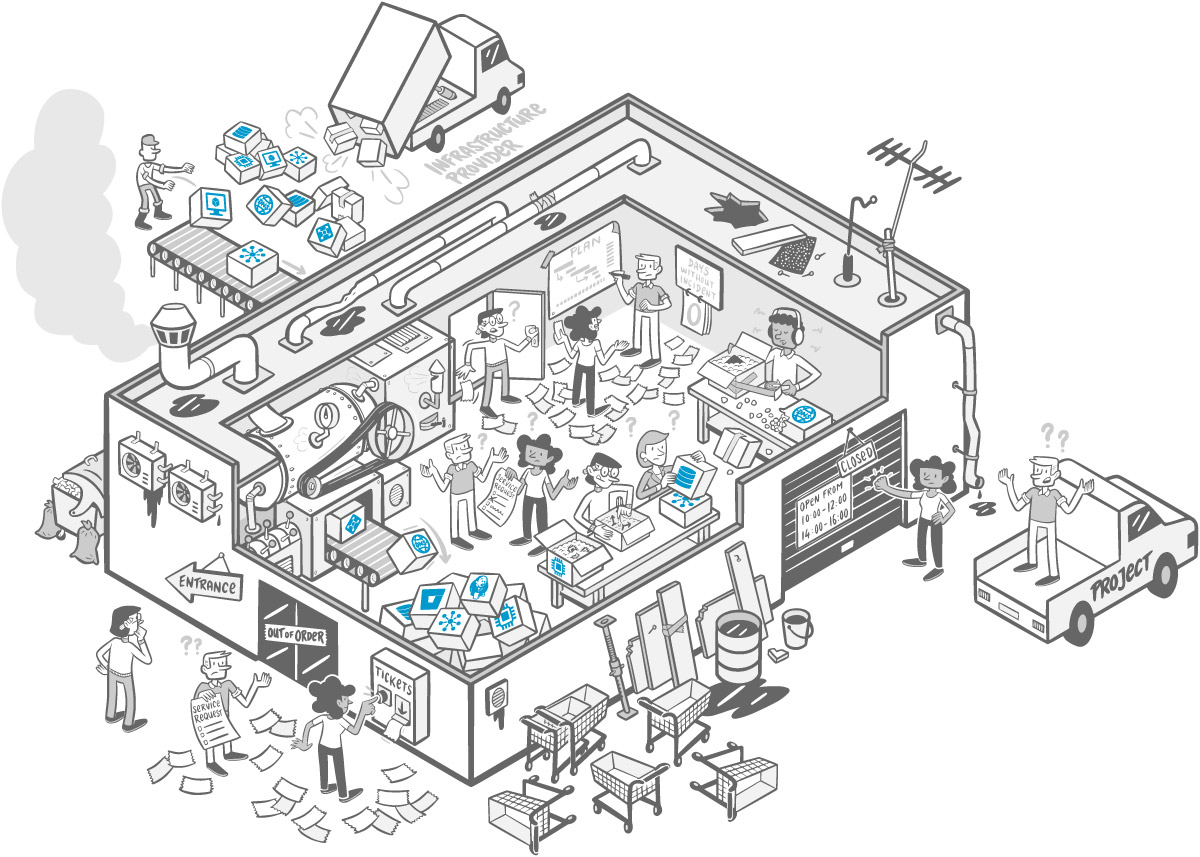
Warum DevEx jetzt?
Vor allem der „War for Talents“ macht DevEx zum kritischen Faktor: Topentwickler:innen wählen Arbeitgeber, die effiziente Arbeitsumgebungen bieten. Eine aktuelle Umfrage unter 200 Inhouse-Developern ergab, dass 58 Prozent über einen Jobwechsel nachdenken, weil veraltete Tech-Stacks ihre Produktivität bremsen [2]. Fast die Hälfte hat im letzten Jahr konkret gekündigt oder wollte kündigen aus Frust über langsame Prozesse, schlechte Tools oder aufwendige Legacy-Systeme. Der CTO des Headless-CMS-Anbieters Storyblok kommentiert: „Die Botschaft an Unternehmen ist klar – veraltete Stacks machen eure Entwickler so unzufrieden, dass sie kündigen“. Kurz: Wer die Bedürfnisse seiner Entwicklungsteams ignoriert, riskiert Innovationsfähigkeit und Talentabwanderung.
Eine hervorragende DevEx zündet hingegen einen positiven Kreislauf: Zufriedene Entwickler sind produktiver, innovativer – und bleiben länger im Unternehmen [1]. Atlassian stellte fest, dass „Entwickler-Joy“ die Produktivität steigert, weil Entwickler in einen Flow-Zustand kommen, wenn sie sich nicht ständig mit schlechten Systemen auseinandersetzen müssen [4]. In einem solchen „frictionless flow“ können Teams ihre Energie auf kreative Lösungen statt auf Toolprobleme verwenden – was wiederum schneller zu neuen Features und Wettbewerbsvorteilen führt. Das Ergebnis sind höhere Kundenzufriedenheit durch schnellere Releases und höhere Mitarbeiterzufriedenheit. DevEx wirkt somit als Multiplikator für Business-KPIs (Time-to-Market, Qualität, Umsatz) und „People“-KPIs (Motivation, Bindung, Recruiting).

Reibung raus, Fokus rein
Power-Workshops zu Developer Experience (22. - 26. Juni 2026, München)
Was gute DevEx ausmacht
Developer Experience umfasst die Gesamtheit der Erlebnisse, die Entwickler:innen während ihrer Arbeit in einem Unternehmen haben – vom Onboarding über das Coding, das Testing, das Deployment bis hin zum Betrieb [5]. Eine gute DevEx bedeutet, dass es möglichst wenig Reibungspunkte im täglichen Entwicklungsprozess gibt, damit sich Entwickler:innen auf das Lösen von fachlichen Problemen konzentrieren können und regelmäßig in den Flow gelangen. In der Praxis kämpfen Entwicklerteams jedoch oft mit unnötigen Hürden wie langwierigen Set-up-Prozessen, fragmentierten Toollandschaften, manuellen Freigaben, unklarer Dokumentation oder Wartezeiten auf andere Teams. Solche Friktionen erhöhen die kognitive Last, also den mentalen Aufwand, um die eigentliche Arbeit zu erledigen. Die Folge sind Kontextwechsel, Unterbrechungen und Frustration, was die Produktivität direkt senkt.
Typische „Developer Frictions“ lassen sich entlang der Developer Journey analysieren [6]. Beispiele:
-
Onboarding: Wie schnell kann ein:e neue:r Entwickler:in erstmals Code in Produktion bringen? Wenn erstmal wochenlang Zugänge beantragt, Tool-Set-ups installiert und Prozesse erlernt werden müssen, ist das ein schlechter Start in die DevEx. Elite-Organisationen schaffen es hingegen, dass neue Teammitglieder innerhalb weniger Stunden eine lauffähige Entwicklungsumgebung haben und erste Änderungen deployen können – u. a. durch automatisierte Set-up-Skripts und eine umfassende Starter-Dokumentation [7].
-
Discoverability: Finden Entwickler:innen leicht die Informationen, die sie benötigen (Services, APIs, Ansprechpartner)? In gewachsenen Organisationen kostet die Frage „Wo finde ich was?“ viel Zeit [8]. Ein Developer-Portal mit zentralem Service Catalog (wie z. B. Spotifys Backstage) löst dieses Problem, indem es alle Komponenten und Dokumentationen an einem Ort auffindbar macht [8]. So entfallen die Reibungsverluste durch Sucherei, und Verantwortlichkeiten sind transparent.
-
Workflow und Wartezeiten: Wie nahtlos ist der Weg vom Code bis zum Deployment? Jeder manuelle Hand-off – etwa das Warten auf QA-Tester, auf manuelle Infrastrukturprovisionierung oder Change-Advisory-Boards – unterbricht den Flow. Unternehmen mit hoher DevEx automatisieren Routineschritte in CI/CD-Pipelines und reduzieren so Feedbackzyklen erheblich. Dadurch wird Entwickler:innen ein „Flow State“ ermöglicht, in dem sie ungestört arbeiten und schnelle, kontinuierliche Rückmeldung von Tests und Monitoring erhalten.
-
Kognitive Komplexität: Müssen sich Teams mit Infrastrukturproblemen, Deploy-Skripten oder Konfigurationschaos herumschlagen? Oder abstrahiert eine Plattform diese Aufgaben für sie? Jede nicht domainrelevante Aufgabe erhöht die kognitive Last. Eine integrierte, konsistente Toolchain kann diese Last von den Teams nehmen. Laut Team Topologies sollte eine Plattform genau das tun: die Komplexität der Infrastruktur von den Produktteams fernhalten, um deren kognitive Last zu reduzieren und Fokus zu ermöglichen [9].
Der Schlüssel zu einer guten DevEx liegt also in der Identifizierung von Reibungspunkten und dem gezielten Entfernen dieser Hindernisse. Entwicklerportale, Selfservice-Automatisierung und klare Golden Paths (dazu gleich mehr) sorgen dafür, dass „der richtige Weg der einfachste ist“. Wenn ein Entwickler bzw. eine Entwicklerin z. B. einen neuen Microservice aufsetzen möchte, sollte das ohne Ticketmarathon in wenigen Klicks möglich sein – von der Repo-Erstellung über die Pipeline bis hin zum Monitoring. Jede optimierte Journey steigert die Flow-Effizienz und damit die Wertschöpfung. Unternehmen sollten daher regelmäßig ihre Developer Journey kartografieren (z. B. via Value Stream Mapping [10]) und sich fragen: Wo verlieren wir Zeit? Wo herrscht Unklarheit? Was frustriert? Nur was sichtbar ist, kann verbessert werden.
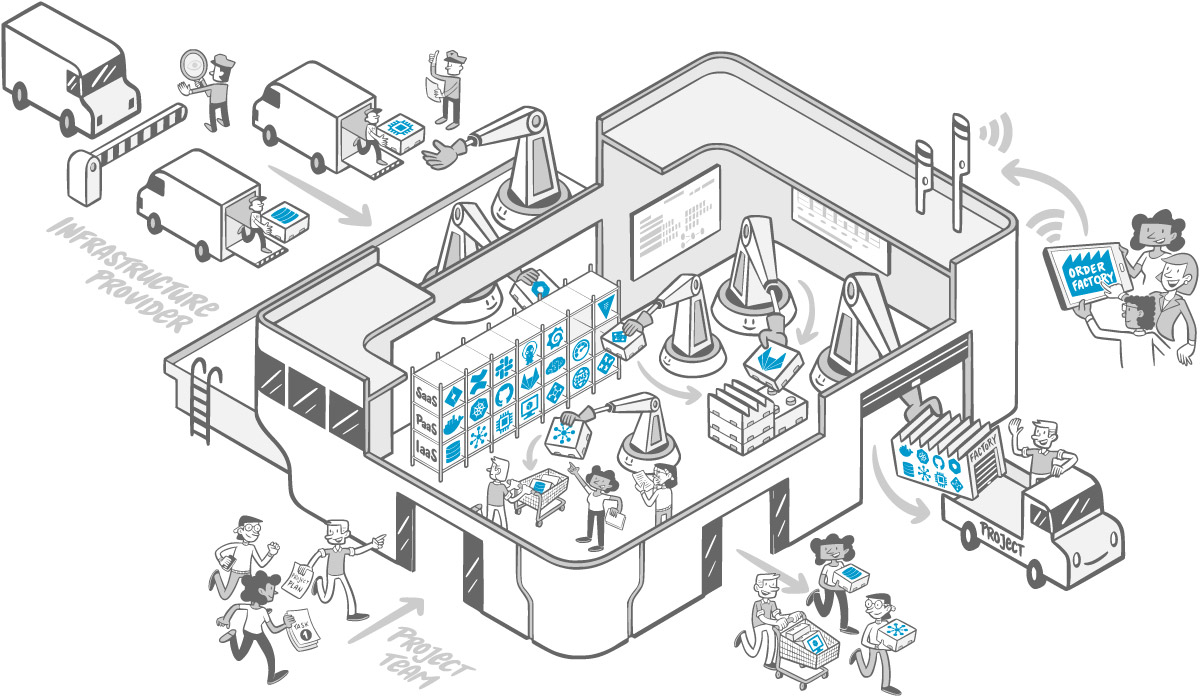
Nicht zuletzt bedeutet gute DevEx auch, eine Kultur zu fördern, in der Entwickler:innen Autonomie mit Verantwortung genießen. Psychologische Sicherheit, Hilfsbereitschaft im Team und blameless Post Mortems tragen zum Wohlbefinden bei und sind ebenfalls Teil der Developer Experience. Produktive Entwicklerteams zeichnen sich durch eine generative Kultur aus, die Zusammenarbeit belohnt und aus Fehlern lernt [3]. DevEx ist somit ein ganzheitliches Thema: Prozesse, Tools und Kultur müssen auf Flow und Entwicklerproduktivität einzahlen (Abb. 2).
Platform Engineering als Hebel
Viele der genannten Friktionen lassen sich durch ein starkes Plattformteam ausräumen. In den letzten Jahren setzen deshalb immer mehr Organisationen auf Platform Engineering: Ein dediziertes Team baut und betreibt eine Internal Developer Platform (IDP) – eine interne Plattform als Produkt für Entwickler:innen, die alle notwendigen Tools und Services integriert. Gartner prognostiziert, dass bis 2026 rund 80 Prozent der Softwareunternehmen Plattformteams einführen werden [11]. High Performer haben diesen Schritt oft schon getan: Unternehmen mit hoher Cloud/DevOps-Reife setzen doppelt so häufig auf Plattformstandards und erzielen damit messbare Vorteile in Produktivität, Qualität und Compliance [11].
Eine IDP stellt den „Developer-Selfservice“ ins Zentrum: Entwicklerteams können Infrastruktur, Deployments und Pipelines eigenständig verwalten, ohne jedes Mal andere Abteilungen hinzuziehen zu müssen. Dadurch werden Wartezeiten und Kontextwechsel enorm reduziert. Ein Fallbeispiel berichtet von einer neu formierten Platform Crew, die während eines einwöchigen Hackathons die häufigsten Deployment-Blocker identifizierte und drei Quick Wins implementierte, darunter eine bessere Pipeline-Automatisierung. Das Resultat waren spürbar kürzere Entwicklungszyklen und begeisterte Entwickler, die dem Plattformteam Standing Ovations gaben [11]. Selfservice befreit Entwickler:innen von Abhängigkeiten und Routineaufgaben. Die Plattform abstrahiert komplexe Prozesse – man kann sie sich als „Leitplanke mit Power-Steering“ vorstellen. Die Entwickler steuern immer noch selbst, aber mit minimalem Aufwand, weil Standardaufgaben automatisch erledigt werden (Abb. 3).
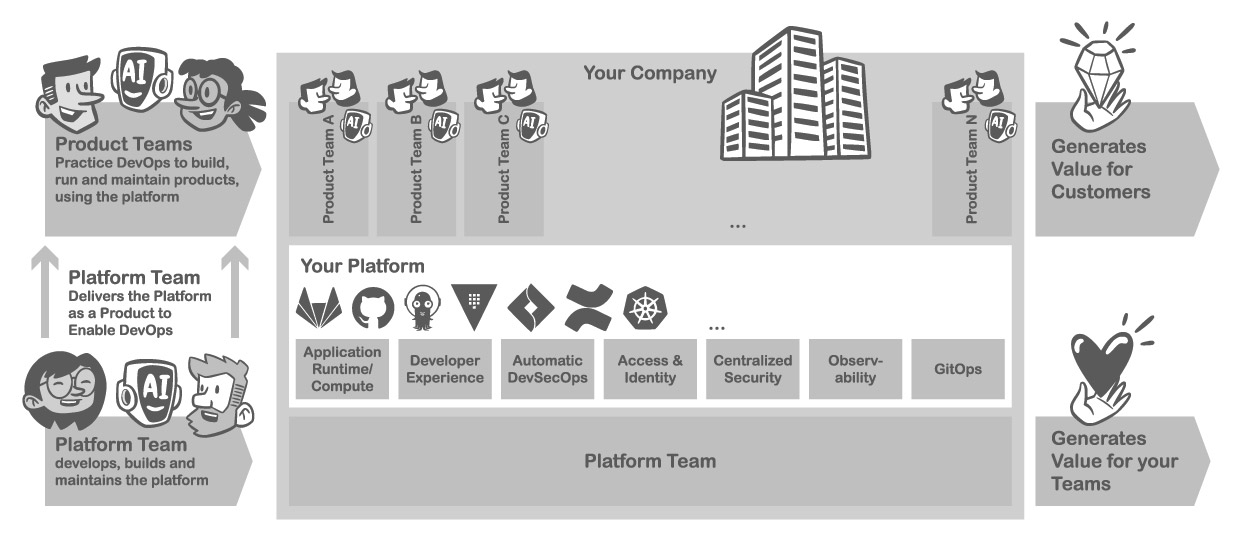
Wichtig dabei ist: Selfservice bedeutet nicht Blackbox. Gute Plattformen bieten Transparenz und lassen Freiheiten, wo es nötig ist. Sie sorgen jedoch dafür, dass Governance und Best Practices automatisch eingebettet sind. Hier kommen Golden Paths und Guardrails ins Spiel.
-
Golden Paths (goldene Pfade) sind vordefinierte, empfohlene Lösungswege für häufig auftretende Aufgaben, wie beispielsweise die Erstellung eines Services, die Anbindung einer Datenbank oder die Durchführung eines Deployments. Sie enthalten alles Notwendige ab Werk: Standardarchitektur, Boilerplate-Code, CI/CD Pipeline, Monitoring, Security-Settings usw. Spotify prägte diesen Begriff, als das Unternehmen Golden Paths für seine Entwickler definierte, um die häufigsten Service-Typen konsistent aufzusetzen. Wenn Entwickler dem Golden Path folgen, erhalten sie „Secure & Compliant by Default“, d. h., die Plattform setzt automatisch alle nötigen Richtlinien und Konfigurationen um. So müssen sich Teams nicht durch Bürokratie kämpfen, sondern haben die Leitplanken schon eingebaut. Golden Paths machen „das Richtige tun“ zum einfachsten Weg und reduzieren die kognitive Last massiv.
-
Als Guardrails (Leitplanken) werden die automatisierten Sicherungen und Richtlinien bezeichnet, die die Plattform durchsetzt. Anstelle nachträglicher Kontrollen, die Wochen dauern, prüft die IDP bei jeder Aktion in Echtzeit, ob beispielsweise alle Tests bestanden wurden oder Security-Policies eingehalten wurden. Ein Beispiel: In einer Cybersecurity-fokussierten Plattform ist es unmöglich, einen Service ohne bestimmte Security-Scans zu deployen – die Pipeline würde den Vorgang blockieren und eine Rückmeldung liefern. Wird beispielsweise eine Datenbank über das Portal angelegt, erzwingt die Plattform automatisch Verschlüsselung, korrekte Netzwerkeinstellungen und Back-ups. Sicherheit und Compliance sind somit standardmäßig integriert, anstatt manuell „drumherum“ aufgebaut zu werden. Guardrails gewährleisten „Freiheit innerhalb fester Grenzen“: Teams können schnell handeln, aber innerhalb klarer, vom System überwachter Leitplanken. Das verhindert Wildwuchs, ohne die Entwickler zu gängeln.
Zu den konkreten Elementen einer IDP zählen unter anderem Developer-Portale (wie Backstage), Service-Templates für neue Projekte, Infrastructure as Code und automatisierte CI/CD Pipelines. Eine solche Plattform wurde beispielsweise beim Schweizer Unternehmen Zühlke aufgebaut. Über ein Portal können Teams hier mit wenigen Klicks neue Infrastruktur und Pipelines bereitstellen und sogar einen KI-Chatbot nutzen, der Entwicklerfragen beantwortet. Alles ist an einem Ort integriert. Das Resultat: Entwickler verlieren keine Zeit mehr durch das Warten auf Tickets oder die Konfiguration von Tools. Die Lead Times schrumpfen, die Deployment-Frequenz steigt und die Organisation erhöht spürbar ihr Tempo [12]. Gleichzeitig stieg die Zufriedenheit der Entwickler deutlich an, als die Plattform eingeführt wurde, wie DORA-Erhebungen bestätigen.
Zusammengefasst ist Platform Engineering ein mächtiger Enabler für DevEx: Es standardisiert wiederkehrende Aufgaben, fördert den Flow durch Selfservice und stellt sichere Standards bereit. Dadurch werden Entwicklerteams entlastet und können sich aufs Coden konzentrieren, während die Plattform im Hintergrund für Konsistenz, Qualität und Sicherheit sorgt. Wichtig ist, die Plattform selbst mit einem Product Mindset zu betreiben. Mehr dazu erfahren Sie im Abschnitt „Operating Model“. Unternehmen, die in diesen Bereich investieren, erhalten eine robuste „Entwicklungshauptstraße“, auf der neue Ideen schnell, sicher und komfortabel bis in die Produktion rollen können.
Stay tuned
Immer auf dem Laufenden bleiben! Alle News & Updates:
KI als Multiplikator
Die rasanten Fortschritte bei KI-gestützten Tools eröffnen eine neue Dimension der Developer Experience. Richtig eingesetzt wirkt KI als Produktivitätsmultiplikator für Entwickler:innen – von der Codeerstellung über Wissensmanagement bis hin zur Betriebsoptimierung. Gleichzeitig müssen Unternehmen Leitplanken setzen, damit KI verantwortungsvoll und sicher zum Einsatz kommt.
-
AI Pair Programming: Code-Assistenztools wie GitHub Copilot, Amazon Q Developer oder Tabnine haben bereits heute einen erheblichen Einfluss. In einer kontrollierten Studie erledigten Entwickler typische Programmieraufgaben mit GitHub Copilot 55,8 Prozent schneller als ohne KI [13]. Solche KI-Copiloten können Boilerplate-Code generieren, beim Schreiben von Unit-Tests helfen oder alternative Implementierungen vorschlagen. Das spart Zeit und hält den Kopf frei für komplexere Probleme. Microsoft berichtet, dass Copilot-Nutzer:innen spürbar weniger mentale Ermüdung zeigen und sich auf kreativere Aufgaben fokussieren können [14]. Wichtig: Die Entwickler:innen behalten die Kontrolle – die KI liefert Vorschläge, die von den Entwickler:innen geprüft und entschieden werden. So werden Routinetätigkeiten beschleunigt, ohne die Codequalität zu gefährden. Unternehmen sollten evaluieren, wie solche Tools ihre Teams unterstützen können und parallel dazu Richtlinien erarbeiten, beispielsweise für den Umgang mit generiertem Code und Lizenzfragen.
-
Wissens-Retrieval und ChatOps: Ein enormes Potenzial liegt im Einsatz von Large Language Models (LLMs) für das firmeninterne Wissensmanagement. Das Stichwort lautet hier RAG (Retrieval-augmented Generation) – also KI, die mit den internen Dokumentationen, Wiki-Inhalten und Code-Repositorys gekoppelt ist. So lassen sich Chatbots entwickeln, die spezifische Entwicklerfragen in Sekunden beantworten, beispielsweise „Wie konfiguriere ich SSO in unserem Auth-Service?“ oder „Welche Funktion validiert Payment-Transaktionen?“. Anstatt in Confluence, Tickets oder Slack-Threads zu suchen, kann ein DevGPT die Antwort samt Codebeispiel direkt geben – basierend auf dem firmeneigenen Knowledge Graph. Erste Unternehmen experimentieren damit erfolgreich: Bei Zühlke wurde ein KI-Chatbot in die interne Plattform integriert, der Fragen zu Best Practices, Codebeispielen oder technischen Problemen beantwortet [12]. Auch der Trend ChatOps geht in diese Richtung: Bots in Kommunikationstools, die Status abfragen oder Deployments auslösen. Durch KI werden diese Bots immer leistungsfähiger. Dabei muss sichergestellt sein, dass die Antworten verlässlich sind (ggf. mit Quellenangabe) und vertrauliche Informationen geschützt bleiben. Ein Vorteil ist, dass solche Assistenten Senior-Entwickler entlasten, weil weniger Mentoring-by-FAQ nötig ist und Neulinge die Antworten schneller selbst finden. Wissens-KI verkürzt somit das Onboarding und Troubleshooting und fördert einen kontinuierlichen Lernfluss.
-
Policy Guardrails für KI: Der Einsatz von KI bringt auch Risiken mit sich – von unsauberem Code bis hin zum Datenschutz. Daher sollten Unternehmen Guardrails definieren. Welche Daten dürfen KI-Systeme sehen? Dürfen generative Modelle Codevorschläge machen, die offenen Quelltext enthalten? Wie kann verhindert werden, dass Geheimnisse (API-Keys, Kundendaten) im Prompt landen? Hier helfen technische Lösungen und Richtlinien, wie etwa Filter, die verhindern, dass der Copilot Firmen-API-Keys aus dem Repository mitlernt, oder Vorgaben, dass KI-generierter Code stets Codereviews durchläuft. Microsofts Security Copilot zeigt, wie sich ein großes Modell gezielt mit Sicherheits-Know-how und Unternehmensdaten füttern lässt, um sichere Entscheidungen zu treffen. Generell gilt: Die Einführung von KI sollte nicht unkontrolliert erfolgen, sondern strategisch gesteuert werden. Die Cybernetic Enterprise [12] betrachtet KI als integrale Fähigkeit, die durch Automatisierung und Leitplanken unterstützt wird. Ein Beispiel für Governance: Einige Firmen messen die AI Prompt Usage und die Fehlerraten der KI-Vorschläge, um daraus Richtlinien abzuleiten. Andere bauen bewusste „Stoppschilder“ ein, beispielsweise indem CI/CD Pipelines warnen, wenn ein Codeblock zu mehr als 50 Prozent aus generiertem Code ohne Tests besteht. So hält man die Balance zwischen Geschwindigkeit und Sicherheit.
-
AIOps und Observability: KI entfaltet auch im Betrieb ihre Wirkung. Unter dem Begriff AIOps werden ML-Modelle eingesetzt, um aus Monitoringdaten und Logs automatisch Erkenntnisse zu gewinnen. Dazu gehören die Anomalie-Erkennung in Metriken, das automatische Clustern von Fehlermeldungen und die Vorhersage von Engpässen. Moderne Observability-Plattformen verfügen oft über KI-Features – beispielsweise Datadog Watchdog oder Dynatrace Davis –, die ungewöhnliche Muster erkennen und Alarm schlagen, bevor ein größerer Ausfall entsteht. KI kann bei Incidents die Root-Cause-Analyse beschleunigen, indem sie Logspuren korreliert oder vergangene, ähnliche Störungen heranzieht. Auch Chatbots helfen im Incident Response, etwa durch ChatOps-Befehle zur Skalierung eines Services während eines Traffic-Peaks. Über den gesamten SDLC hinweg finden sich Ansätze: Testautomation mit KI (Tools, die anhand von Codeänderungen priorisieren, welche Tests auszuführen sind, z. B. Launchable), Codereview-Assistenten oder Architekturdokumentation. Diese KI-Features tragen zu einer verbesserten DevEx bei, indem sie den „undifferentiated heavy lifting“ weiter reduzieren.
Fazit: KI verändert den Entwickleralltag nachhaltig. Einerseits kann sie enorme Produktivitätssprünge bringen – erste Zahlen deuten auf eine Zeitersparnis von 20-50 Prozent bei vielen Aufgaben hin [13] –, andererseits kann sie die Developer Happiness steigern, weil repetitive Arbeiten entfallen. Allerdings erfordert das einen gezielten und maßvollen Einsatz: Unternehmen müssen KI-Enablement betreiben, d. h. Teams schulen, geeignete Anwendungsfälle auswählen und technische Leitplanken etablieren. Dann wird KI zum natürlichen Bestandteil der Entwicklungsplattform: als kollaborativer Assistent, der Vorschläge macht, auf Risiken hinweist und das Lernen erleichtert. In Kombination mit einer starken Plattform und DevOps-Praktiken entsteht so die Cybernetic DevEx – eine lernende, adaptive Umgebung, in der Mensch und KI zusammen Höchstleistungen erbringen können [10].
Messen, was zählt
„You can’t improve what you don’t measure“ – dieses Managementmantra gilt auch für DevEx-Initiativen. Um Fortschritte sichtbar zu machen und die richtigen Hebel zu justieren, sind sinnvolle Metriken notwendig. Allerdings war die Messung der Entwicklerproduktivität lange umstritten. Schlechte Ansätze fokussieren sich auf sogenannte „Vanity-Metriken“ wie Lines of Code, Commits pro Tag oder Story Points. Diese sagen wenig über den tatsächlichen Wert aus und führen oft in die Irre [1]. Stattdessen hat sich ein Set bewährter Kennzahlen etabliert, um Software-Delivery und Developer Experience zu quantifizieren:
-
DORA’s Four Key Metrics: Aus der DevOps-Forschung (DevOps Research & Assessment) stammen vier Metriken, die Software-Delivery-Performance messen [1]. Deployment Frequency (wie oft produktiv ausgeliefert wird) und Change Lead Time (Zeit von Commit bis Release) stehen für den Durchsatz; Mean Time to Restore (MTTR) und Change Failure Rate (Fehlschlagsquote von Changes) für die Stabilität [1]. Diese Metriken sind heute industrieller Standard. Unternehmen sollten ihren Status hier kennen (beispielsweise aus Jira/GitLab-Pipelines ableitbar) und als Benchmark nutzen. Verbesserungen der DevEx – etwa durch Automatisierung – spiegeln sich direkt in besseren DORA-Metriken wider (höhere Deployment-Frequenz, schnellere Recoveries). So sank bei Atlassian durch gezielte Investitionen in Tools die Commit-to-Deploy-Zeit in manchen Bereichen um 90 Prozent [4]. Es besteht eine starke Korrelation zwischen DORA-Metriken und Performance: Eliteteams deployen mehrfach täglich, während Low-Performer das alle sechs Monate tun [3]. Die MTTR liegt bei Stunden, während sie bei Low-Performern Monate beträgt. Diese gewaltigen Unterschiede zeigen, was möglich ist, und liefern einen Business Case für Investitionen in die DevEx.
-
SPACE-Framework: Da reine Throughput-Metriken nicht alle Aspekte abbilden, wurde 2021 das SPACE-Modell vorgeschlagen [9]. Es definiert fünf Dimensionen, um die Entwicklerproduktivität ganzheitlich zu betrachten: „Satisfaction & Well-being“, „Performance“ (z. B. Qualität, Outcome), „Activity“ (Outputmetriken wie Commits – mit Vorsicht zu genießen), „Communication & Collaboration“ sowie „Efficiency & Flow“ [9]. Die Kernidee: Produktivität ist multidimensional, weshalb ein Portfolio von Metriken betrachtet werden muss, oft mit Trade-offs [9]. Für DevEx sind insbesondere Zufriedenheit, Effizienz und der Flow-Zustand relevant. Praktisch bedeutet das, neben harten Zahlen auch weiche Faktoren zu verfolgen, z. B. regelmäßige Entwicklerumfragen (Developer Satisfaction) oder Zeitanalysen, die aufzeigen, wie viel Prozent der Zeit in Deep Work vs. Warten/Meetings gehen (Flow). Laut Forschung gehen hohe wahrgenommene Produktivität und Zufriedenheit Hand in Hand [9].
-
DevEx-Surveys & Developer NPS: Viele Organisationen führen quartalsweise Umfragen zur Developer Experience durch. Ähnlich wie beim Mitarbeiter-NPS wird die Frage gestellt: „Wie wahrscheinlich ist es, dass du die internen Entwicklungsumgebungen einem Kollegen empfehlen würdest?“ Ein interner DevEx-NPS (analog zum Kundennetzpromotorwert) quantifiziert die Stimmung. DORA 2024 empfiehlt solche Befragungen, um frühzeitig Warnsignale zu erkennen, falls die interne Plattform nicht gut ankommt. Auch gezielte Fragelisten (wie die SPACE-Umfrage von GitHub) werden eingesetzt. GitHub selbst hat herausgefunden: Developer Satisfaction ist der beste Prädiktor für Produktivität – glückliche Entwickler liefern nicht nur mehr, sondern auch besseren Code [1]. Daher trackt GitHub diesen Wert intern sehr genau. Organisationen sollten also den Puls ihrer Dev-Teams fühlen: „Was läuft gut? Wo klemmt’s?“ – und die Veränderungen über die Zeit messen.
-
„Before vs. After“-Metriken: Wenn man DevEx-Initiativen startet, lohnt es sich, Baseline-Metriken zu erheben und diese nach beispielsweise drei, sechs oder zwölf Monaten erneut zu messen. Beispiele: Onboardingzeit für neue Entwickler:innen (hat sich diese z. B. von vier Wochen auf eine Woche verkürzt, seitdem eine IDP eingeführt wurde?), durchschnittliche Build-Zeit (ging sie durch bessere Hardware oder Pipelines zurück?), Anzahl Deployments/Monat pro Team (stieg diese durch Selfservice?). Auch qualitative Rückmeldungen zählen: Verbessert sich die Stimmung im Team? Hat sich die „Tickethölle“ laut Entwickleraussagen verringert? Ein solcher Soll-Ist-Vergleich zeigt, ob Quick Wins wirklich wirken. Nicht zuletzt können Antimetriken Hinweise geben. So kann beispielsweise die Paging-Frequenz im Betrieb anzeigen, ob die Zuverlässigkeit gestiegen ist, weil es weniger nächtliche Pager-Duty-Alarme gibt.
Es ist wichtig, Metriken sinnvoll zu verknüpfen und nicht isoliert zu betrachten. Ein Team, das sich ausschließlich auf die Deploy-Häufigkeit konzentriert, könnte an Qualität einbüßen – deshalb ist es wichtig, immer den Kontext zu berücksichtigen (vgl. SPACE). Metriken dienen als Diagnosewerkzeug und nicht als Selbstzweck. Insbesondere sollten daraus keine individuellen Leistungsrankings gemacht werden, da das die Kultur zerstört. Stattdessen: Team-Level-Trends beobachten und als Gesprächsgrundlage nutzen: „Wie können wir die Cycle Time von einer Woche auf einen Tag verbessern? Welche Bottlenecks blockieren uns?“). Die DORA/Accelerate-Forschung zeigt, dass sich Verbesserungen dieser Kennzahlen unmittelbar in einer besseren Performance der gesamten Organisation niederschlagen. Das sollte das Ziel sein und nicht die Optimierung der Metriken um ihrer selbst willen.
Operating Model
Damit DevEx mehr als nur ein Strohfeuer einzelner Tools wird, ist ein tragfähiges Betriebsmodell erforderlich. Schließlich handelt es sich um einen kontinuierlichen Verbesserungsprozess, der mit einer agilen Transformation vergleichbar ist und passende Strukturen, Verantwortlichkeiten und Ressourcen erfordert. Folgende Aspekte sind dabei essenziell:
-
Plattform als Produkt mit klarer Ownership: Ein häufiger Fehler ist es, die interne Entwicklerplattform wie ein einmaliges IT-Projekt zu behandeln. Erfolgreiche Unternehmen betrachten die Plattform hingegen als eigenes Produkt, bei dem die Entwicklerteams die „Kunden“ sind [6]. Das bedeutet, dass es dedizierte Rollen gibt, zum Beispiel einen Platform Product Owner/Manager, der die Anforderungen der internen Nutzer versteht und priorisiert – analog zum Produktmanagement für externe Kunden. Das Plattformteam sollte cross-funktional aufgestellt sein (Entwicklung, Ops, Security, eventuell UX) und die Mission haben, die DevEx kontinuierlich zu verbessern. Klare Ownership ist entscheidend: Ohne jemanden, der sich um die Plattform kümmert und sie vorantreibt, verfällt diese leicht oder verfehlt die Bedürfnisse [6]. Daher sollte die Verantwortung auf C-Level verankert werden (z. B. berichtet der Head of Developer Platform an den CTO) und Plattform-OKRs definiert werden. Ein Indikator für reife DevEx-Organisationen ist, dass sie Plattform-KPIs und SLOs haben, beispielsweise „Onboarding eines neuen Teams in unter einer Stunde“. Das Plattformteam sollte sein Service-level gegenüber Entwickler:innen kennen und managen wie ein Produktanbieter.
-
Budget und Ressourcen: DevEx-Initiativen erfordern initiale Investitionen (Toollizenzen, eventuell Cloud-Kosten für neue Pipelines, interne Entwicklung der Plattform), die sich jedoch mittel- bis langfristig durch höhere Effizienz wieder auszahlen. Wichtig ist, dass der CIO/CTO hierfür gezielt Budget bereitstellt und nicht versucht, DevEx „nebenbei“ von überlasteten DevOps-Teams umsetzen zu lassen. Einige Organisationen führen ROI-Betrachtungen durch: „Wenn wir das Onboarding um zwei Wochen verkürzen, sparen wir 50 000 Euro pro neuem Entwickler/neuer Entwicklerin“ oder „Ein Deployment-Ausfall weniger pro Monat spart x Umsatz“. Solche Zahlen helfen, das Management von der finanziellen Sinnhaftigkeit zu überzeugen. In jedem Fall muss das Plattformteam die Ressourcen erhalten, um Tools einzuführen, intern zu entwickeln und laufend zu betreiben (manche Firmen behandeln das als eigenes Produktbudget mit laufenden CAPEX/OPEX).
-
Skillset und Rollen: Neben dem Platform Product Manager sind oft Developer Experience Engineers oder Platform Engineers gefragt. Diese Profile kombinieren breite Technikkenntnisse (CI/CD, Cloud, Automation) mit Empathie für die Bedürfnisse von Entwickler:innen. Manche Unternehmen rekrutieren für solche Rollen erfahrene Entwickler:innen aus den eigenen Reihen – sie kennen die Pain Points am besten. Auch Developer Advocates können intern agieren und das Plattformteam mit Feedback versorgen. Wichtig: Diese Rollen sollten von oben her Empowerment genießen, um bestehende Prozesse zu verändern. So muss das Plattformteam beispielsweise in der Lage sein, (in Absprache mit InfoSec) Policies zu definieren, um Standards durchzusetzen.
-
Produkt-Mindset und Feedback-Loops: Ein gutes Plattformteam arbeitet wie ein agiles Produktteam: regelmäßige Bedarfsabstimmungen mit Nutzern (Interviews, Surveys) [6], Priorisierung nach Nutzen (z. B. mit einem DevEx-Backlog, das aus Pain Points gespeist wird) und iterative Releases der Plattform. Beispielsweise wird zunächst ein MVP eines Service-Portals ausgerollt und dann anhand von Entwicklerfeedback ausgebaut. Ein starker Feedback-Loop ist dabei sehr wertvoll: Direktes Feedback aus den Entwicklungsteams (etwa über einen Chat-Channel oder regelmäßige Office Hours des Plattformteams) zeigt, was funktioniert und was nicht [6]. Führende Firmen erheben auch DevEx-KPIs wie den Internal NPS und binden sie in Ziele des Plattformteams ein. So wird DevEx-Verantwortung institutionalisiert.
-
SLOs und SLA gegenüber Entwicklern: Genau wie bei einem externen Produkt sollten für die Nutzer (Entwickler) wichtige Service-level Objectives für die Plattform definiert werden. Beispiele: Plattformverfügbarkeit 99,9 Prozent, durchschnittliche Zeit zur Bereitstellung eines neuen Dev-Umfelds < 30 min, Reaktionszeit auf Supportanfragen (z. B. Plattform-Support-Channel) < 5 min während der Kernzeiten. Diese Kennzahlen signalisieren den Dev-Teams: „Die Plattform-Crew nimmt euch ernst und liefert Quality of Service.“ Einige Organisationen schließen sogar interne SLAs ab, z. B. „Das Plattform-Team garantiert, dass jedes neue Service-Template die neuesten Sicherheitsstandards erfüllt, sonst …“. Natürlich muss man es nicht so formal treiben, aber ein Leistungsversprechen erhöht das Vertrauen. Das Plattformteam sollte sich auch messbar machen, z. B. durch regelmäßiges Reporting dieser SLOs an die Technikleitung.
-
DevEx in der Führungsebene verankern: Langfristig gehört Developer Experience als Kennzahl auf das Dashboard der Unternehmensführung – analog zu Kundenzufriedenheitsindex oder Mitarbeiterengagement. Unternehmen wie Google oder Microsoft nutzen seit Jahren interne Metriken für Developer Productivity, die bis ins Management hinein verfolgt werden [1]. Ein Head of Engineering Productivity oder ein VP Developer Experience in der Organisation kann diesen Fokus institutionalisieren. In kleineren Firmen übernimmt der CTO meist die Rolle des DevEx-Champions. Entscheidend ist, dass die Kultur DevEx als gemeinsames Anliegen sieht: Führungskräfte fragen aktiv nach den Pain Points ihrer Entwickler:innen, feiern Verbesserungen (wie z. B. schnellere Releases) und setzen die Erwartung, dass kontinuierlich an Tooling und Prozessen gearbeitet wird. Continuous Improvement eben – nach innen gerichtet.
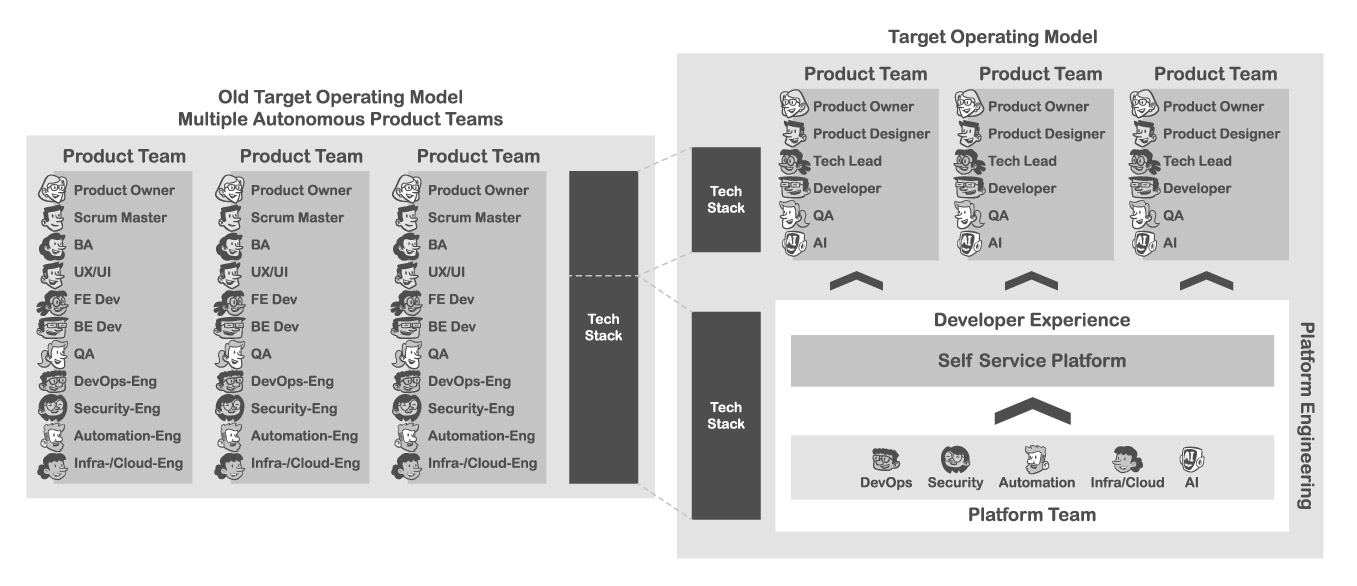
Zusammengefasst muss DevEx also operationalisiert werden, damit es nachhaltig wirkt. Dazu sind klare Verantwortlichkeiten, ein angemessenes Budget und ein Produkt-Mindset erforderlich. Die Plattform ist nie „fertig“, sondern wird kontinuierlich weiterentwickelt, ebenso wie die Bedürfnisse der Entwickler:innen. Mit den passenden Strukturen stellt man sicher, dass DevEx nicht versandet, sondern zum festen Bestandteil der Unternehmens-DNA wird. In einem solchen Umfeld wird die Plattform zum Enabler und Wettbewerbsvorteil, da sie die gesamte Entwicklungsorganisation schneller und adaptiver macht (Abb. 4).
Schlussgedanke
Developer Experience ist weit mehr als nur ein IT-Optimierungsprojekt. Sie ist entscheidend dafür, ob Unternehmen ihre Innovationskraft voll ausschöpfen und die besten Talente halten können. Wer jetzt in Platform Engineering, KI-Assistenz und eine DevEx-orientierte Kultur investiert, schafft nicht nur reibungslose Abläufe, sondern auch einen dauerhaften Wettbewerbsvorteil. Deshalb sollten CIOs und CTOs DevEx nicht delegieren, sondern zur Chefsache machen. Denn zufriedene Entwickler:innen sind die Grundlage für digitale Spitzenleistungen.
Links & Literatur
[2] https://www.techradar.com/pro/many-in-house-developers-are-ready-to-quit-over-inadequate-tech
[3] https://cloud.google.com/resources/state-of-devops
[4] https://www.atlassian.com/blog/atlassian-engineering/the-key-to-unlocking-developer-productivity .
[5] https://www.analyticsverse.com/developer-experience
[7] https://www.gitpod.io/blog/developer-onboarding-key-metrics-to-track
[8] https://www.thoughtworks.com/en-us/insights/articles/friction-developer-portals-solve
[9] https://queue.acm.org/detail.cfm?id=3454124
[10] https://leanpub.com/CyberneticEnterprise/
[11] https://faun.pub/devex-quick-wins-for-platform-team-success-25950136c006
[12] https://www.youtube.com/watch?v=9HIoUOqTYr4
🔍 Frequently Asked Questions (FAQ)
1. Was ist Developer Experience (DevEx)?
Developer Experience (DevEx) beschreibt alle Erfahrungen von Entwickler:innen im gesamten Softwareentwicklungsprozess – vom Onboarding über Entwicklung und Testing bis hin zu Deployment und Betrieb. Ziel ist es, Reibung zu reduzieren, damit Entwickler schneller und effizienter im „Flow“ arbeiten können.
2. Warum ist DevEx für Unternehmen wichtig?
DevEx ist ein entscheidender Wettbewerbsfaktor, weil sie direkt die Produktivität, Innovationsgeschwindigkeit und Mitarbeiterzufriedenheit beeinflusst. Gute DevEx führt zu schnelleren Releases und besseren Geschäftsergebnissen, während schlechte DevEx zu Verzögerungen und hoher Fluktuation führt.
3. Was ist Platform Engineering im Zusammenhang mit DevEx?
Platform Engineering ist ein Ansatz, bei dem ein dediziertes Team eine Internal Developer Platform (IDP) aufbaut. Diese Plattform ermöglicht Self-Service für Entwickler:innen und automatisiert wiederkehrende Aufgaben wie Deployments, Infrastruktur und CI/CD-Prozesse.
4. Was sind Golden Paths in der Softwareentwicklung?
Golden Paths sind standardisierte und empfohlene Wege, um Software zu entwickeln und zu betreiben. Sie enthalten Best Practices, Templates, CI/CD-Pipelines und Sicherheitsstandards, sodass Entwickler automatisch „den richtigen Weg“ nutzen.
5. Wer profitiert von einer guten Developer Experience?
Von guter DevEx profitieren nicht nur Entwickler:innen, sondern das gesamte Unternehmen. Dazu gehören CIOs, CTOs, Produktteams und letztlich auch Kund:innen, da Software schneller, stabiler und in besserer Qualität ausgeliefert wird.
6. Welche Rolle spielt KI in der Developer Experience?
KI unterstützt Entwickler:innen als Produktivitätsmultiplikator. Tools wie KI-Coding-Assistenten, Chatbots oder AIOps-Systeme helfen beim Schreiben von Code, beim Finden von Informationen und bei der Automatisierung von Betriebsaufgaben.
7. Wie wird Developer Experience gemessen?
DevEx wird mit verschiedenen Methoden gemessen, z. B. mit DORA-Metriken (Deployment-Frequenz, Lead Time, Fehlerquote, Wiederherstellungszeit) oder dem SPACE-Framework. Zusätzlich werden Entwicklerbefragungen und interne NPS-Werte genutzt, um Zufriedenheit und Produktivität zu bewerten.



